
Cognitive services の Computer Vision API は Logic Apps にコネクタが用意されているのでノンコーディングで利用することができます。
今回はComputer Vision API の OCR (光学式文字認識:画像に含まれる文字列をテキストデータとして抽出) 機能を最短手順で利用する手順です。
事前準備
本ワークフローを作成する前に、以下の準備が必要です。
OneDriveの準備
サインインできるOneDrive( https://onedrive.live.com/about/ja-jp/ )アカウントを用意します。
以下のフォルダを作成しておきます。
- logicapps_ocr … 画像(テキストを抽出したい)を格納するフォルダ
- logicapps_txt … 抽出したテキストファイルを格納するフォルダ
Computer Vision APIの準備
Computer Vision APIの準備をしておきます。
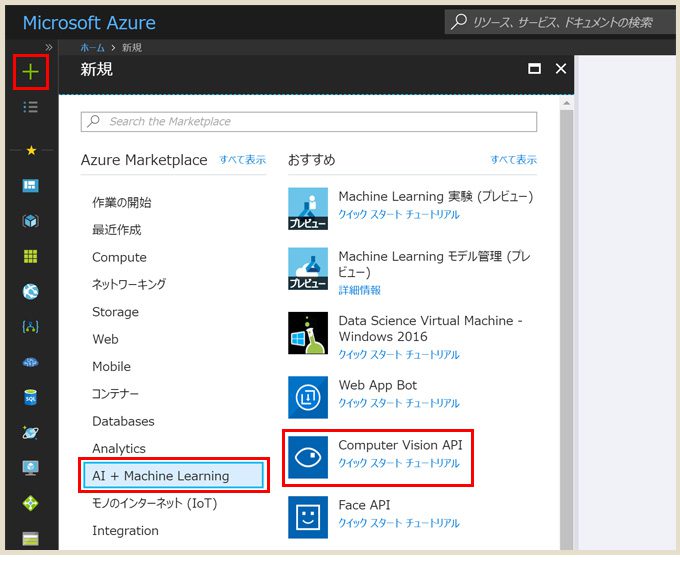
左メニューの「+」クリック → AI + Machine Leaning → Computer Vision API をクリック。
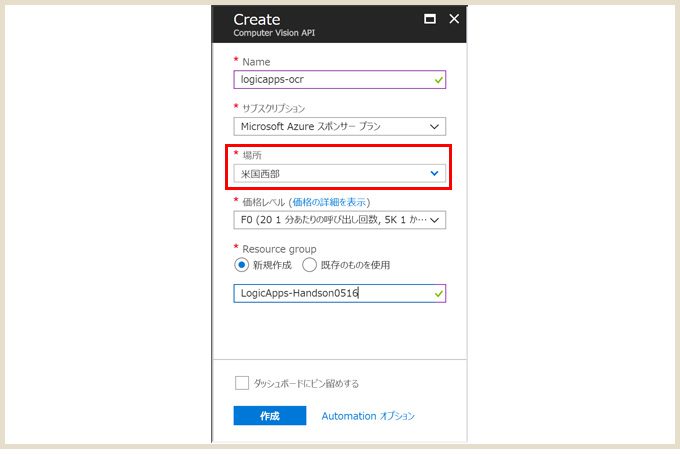
場所(リージョン)は「米国西部」で作成します。また、初めて作成する場合は「F0(無料プラン)」で作成できます。

作成が完了したら、左メニューの「Key」をクリックし、以下の内容を控えておきます。
- NAME
- KEY1
この内容は、Logic Appsのコネクタ使用時に必要になります。
Logic Appsを作成する
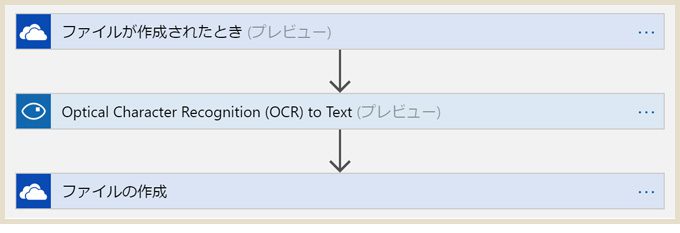
全体のLogic Flowはこのような感じ。たったの3つ!
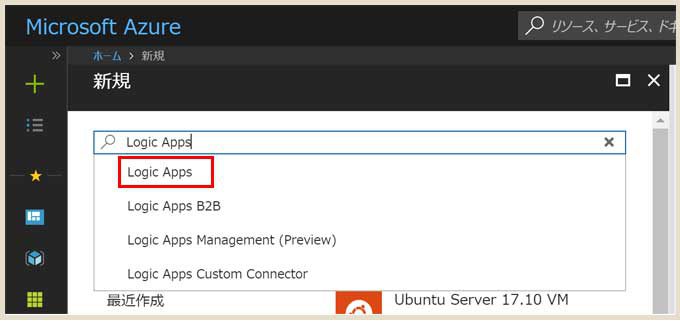
左メニューの「+」クリック → 検索部分に「Logic Apps」と入力して新規作成します。

場所(リージョン)は「米国中西部」で作成します。
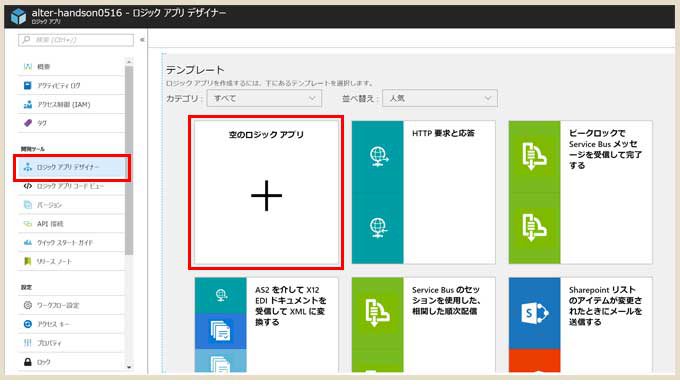
作成できたら「ロジックアプリデザイナー」をクリックして、「空のロジックアプリ」をクリック。
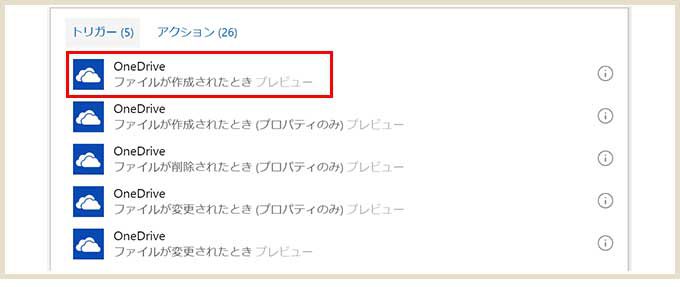
今回はトリガーに「OneDrive – ファイルが作成されたとき」を選択。
初めて接続する際はログインする必要があります。

フォルダーは画像を格納するフォルダ(logicapps_ocr)を選びます。
このフォルダに画像がアップロードされると、画像内のテキストを抽出します。
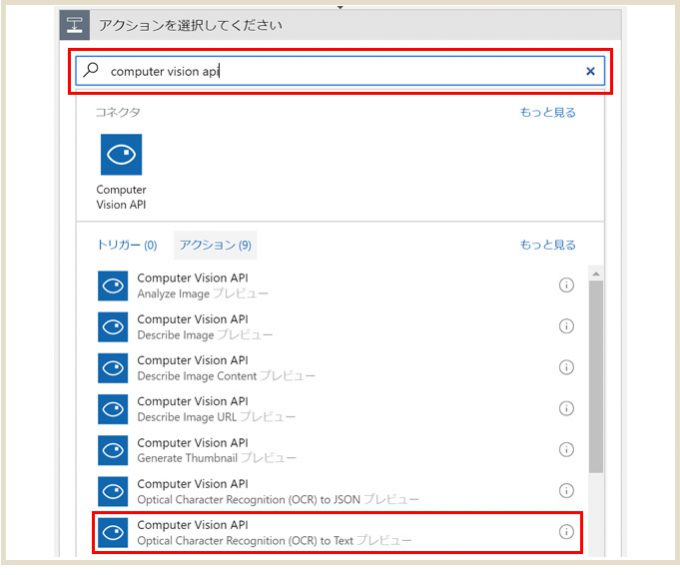
「Computer Vision API」を検索するとコネクタが表示されます。
「Optical Character Recognition(OCR) to Text」を選択。

事前に控えてある「接続名」と「KEY1」の内容を入力します。

接続できるとコネクタがこの表示に変わるので、上記のように設定します。
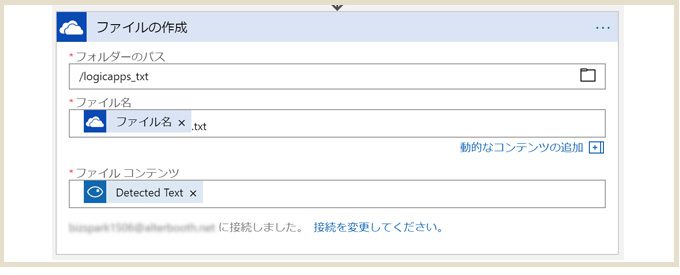
最後に、OneDrive内に画像内から抽出したテキストファイルを出力するようにします。
OneDriveコネクタを選択し、テキストファイルを格納するフォルダ(logicapps_txt)を選びます。
実際に動かしてみる
今回はOneDriveに3分ごとにアクセスするように設定していますが、画像をアップロード後すぐに結果を見たい場合は以下の方法で確認してください。
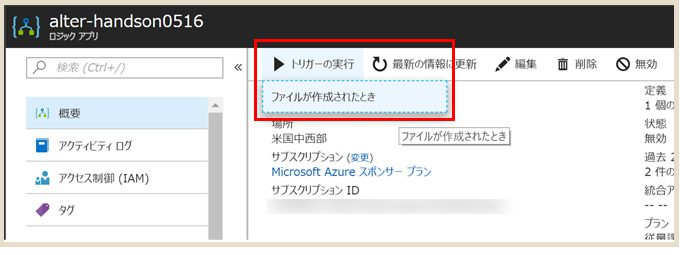
OneDriveに画像をアップロードしたあと、「概要」の「トリガー実行(ファイルが作成されたとき)」をクリックすると、すぐに実行できます。
OneDrive内に出力されるテキストファイルを確認してみてください。
最後に
今回はOneDriveに3分ごとにアクセスするように設定していますが、これは止めるまで課金され続けます。ですので、利用しない場合は「無効」に設定変更しておきましょう。

参考ページ